作者|林易
编辑|重点君
就在刚刚,豆包专业版正式上线了。
一个比较直观的变化,就是现在的豆包里多了个办公任务模式:
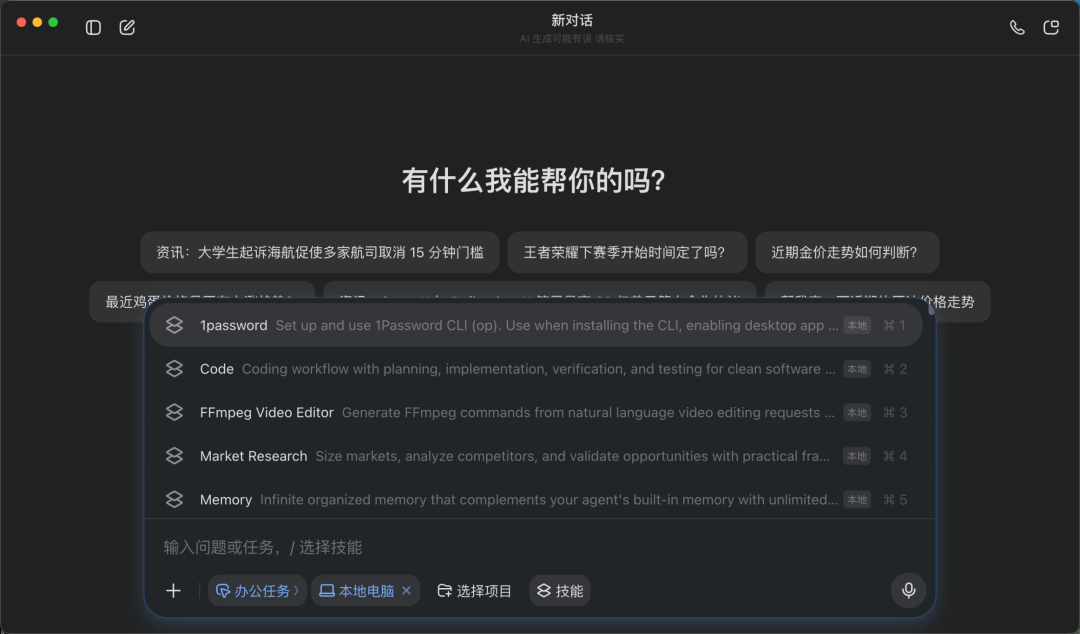
从界面看,输入框旁边新增了“本地电脑”入口,也有Skills技能菜单。用户可以让它连接本地电脑,也可以根据任务选择不同技能,比如代码、市场研究、视频处理、记忆管理等。
这个形态有点像面向普通用户的Harness。
模型负责理解目标、拆解任务和生成方案;办公任务模式负责连接本地电脑、浏览器、本地文件和Skills技能,把模型能力封装进一个个可执行的工作流。
但比起某个功能上架来说,此举更是意味着“豆包收费”这件事,终于是尘埃落定。因此现在需要关注的问题就变成了当价格真正摆上台面,用户到底会为什么买单?
从豆包公布的价格来看,目前一共分了三档,分别是标准套餐连续包月68元、加强套餐连续包月200元,以及高级套餐连续包月500元。
当然,权益也是随之分层的。例如标准套餐包含免费版所有权益,接入2.1 Pro模型,办公任务、专家模式等功能额度为免费版5倍以上;加强套餐是标准套餐4倍额度;高级套餐则是标准套餐10倍额度;免费用户仍然可以体验接入2.1 Turbo模型的办公任务模式。
当我们把这几条信息放在一起,豆包专业版的轮廓就比较清楚了。免费版继续覆盖大部分日常需求,专业版则面向更高频、更重度、更复杂的生产力场景,把2.1 Pro、更高额度和办公任务模式打包在一起。
不过对于“Seed 2.1值不值这个价”的问题,我们不能只看月费数字和模型榜单。更接近用户体感的判断标准,应当是它能否接过复杂任务,能否帮用户少耗几个小时,能否把一段原本需要来回切换文件、浏览器、表格、代码和PPT的工作流,推进到一个可交付结果。
因为如果豆包专业版卖的只是“更多次数”,500元档的说服力会比较有限。若它对应的是更强模型、更高额度、更多工具调用,以及一套能跑任务的办公环境,这件事就进入了生产力工具的讨论框架。
所以到了这一步,“值不值”不再只是模型参数问题。用户花钱买的,也不只是2.1 Pro模型和更高额度,而是一个可以调动工具、调用技能、处理本地文件、生成可视化结果的任务执行环境。
三组实测,看它有没有交付感
为了验证豆包专业版好不好用,我们设计了三类测试:
第一类,是电商经营数据分析,看它能不能把一张原始交易表变成管理层能读的业务简报。
第二类,是城市交通数据可视化,看它能不能把一个模糊需求拆成代码任务,并交付可运行的小工具。
第三类,是英伟达年报分析,看它能不能从长PDF里提取事实、整理结构,并区分公司表述和媒体判断。
这三个任务,对应专业用户更在意的三件事,分别是读懂数据、写出工具、处理复杂材料。
前两个case,我们是在OpenCode里调用Seed 2.1 Pro API完成测试。第三个case,则是在豆包桌面端办公任务模式里,用免费用户也可以体验的2.1 Turbo完成测试。
测试1:电商数据能不能变成经营简报
第一个任务,我们给Seed 2.1 Pro一份公开的Online Retail电商交易数据,让它从数据质量检查开始,完成GMV、订单数、客单价、复购客户、国家分布、商品排行和RFM客户分层分析。
Prompt如下:
Plain Text
你是一名电商业务分析师。请基于我上传的Online Retail交易数据,完成一份面向管理层的经营分析简报。
要求如下:
1.先检查数据质量,包括缺失值、异常值、退货订单、负数数量、异常单价等;
2.计算整体GMV、订单数、客单价、购买客户数、复购客户数;
3.按月份分析GMV变化趋势,找出增长或下滑明显的月份,并尝试解释可能原因;
4.按国家分析销售贡献,找出英国之外的高潜力市场;
5.按商品分析Top 20销售额商品、Top 20销量商品,并说明二者差异;
6.做一个简单RFM客户分层,把客户分成高价值客户、潜力客户、沉睡客户和低价值客户;
7.基于分析结果,给出5条可以执行的经营建议;
8.最后用300字总结:如果你是这家电商公司的负责人,下个月最应该优先做哪三件事。
注意:
- 所有结论都要有数据依据;
- 不要把相关性写成因果关系;
- 如果数据不足以支撑某个判断,请明确说明。
这个任务的难点不在算几个指标,而在于模型要意识到数据并不干净。
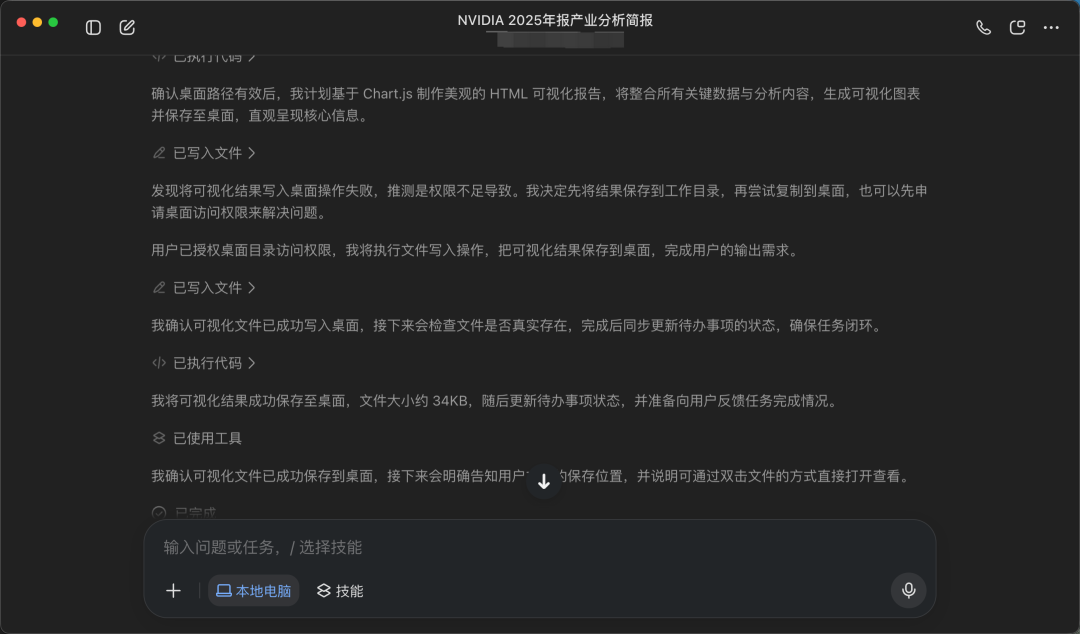
从输出结果看,Seed 2.1 Pro给出了一份比较完整的可视化经营分析报告,内容里不仅有关键指标卡片,也包含数据质量概览、月度GMV趋势、客户分层、Top商品分析、国家与市场分布,以及最后的行动建议。
并且它没有停留在总结数据。比如在数据清理部分,它会把退货、缺失、异常值等问题单独拎出来;在客户分析里,它把客户分成不同层级,进一步给出运营建议;在商品分析里,它还区分了销售额Top和销量Top,避免把“卖得多”和“卖得贵”混在一起。
这类输出已经有明显的交付感。它不一定能直接替代业务分析师,但对于一个高频使用AI的运营、市场或管理者来说,它已经能把“数据清洗—指标计算—业务判断”串成一条完整链路。
测试2:纽约出租车数据能不能做出一个可运行工具
第二个任务更接近AI Coding。
我们让Seed 2.1 Pro基于纽约Yellow Taxi行程数据,生成一个可以本地运行的数据分析小工具。它需要读取数据、清洗异常值、生成图表、汇总成HTML报告,并给出运行方法和测试用例。
Prompt如下:
Markdown
请你帮我基于上传的纽约Yellow Taxi行程数据,做一个可以本地运行的数据分析小工具。
需求如下:
1.使用Python实现;
2.读取我上传的CSV或Parquet文件;
3.自动完成基础数据清洗,包括:
- 删除上车时间晚于下车时间的数据;
- 删除行程距离小于等于0的数据;
- 删除费用小于0的数据;
- 删除明显异常的超长行程;
4.输出以下分析结果:
- 每小时订单量变化;
- 每小时平均车费变化;
- 不同支付方式的订单占比;
- 行程距离和车费之间的关系;
- 工作日和周末订单量对比;
5.生成至少4张可视化图表;
6.将结果汇总成一个HTML报告;
7.代码需要包含清晰注释;
8.请先给出实现思路,再输出完整代码;
9.最后给出运行方法和依赖安装命令;
10.请设计3个测试用例,检查代码是否能处理空文件、缺失字段和异常数据。
注意:
- 不要假设字段一定完整;
- 如果发现字段名和预期不一致,请先列出字段名,再给出兼容处理方案;
- 代码要尽量让非专业程序员也能照着运行。
从最终输出的结果来看,Seed 2.1 Pro给出了一份“NYC Yellow Taxi Trips”可视化报告。
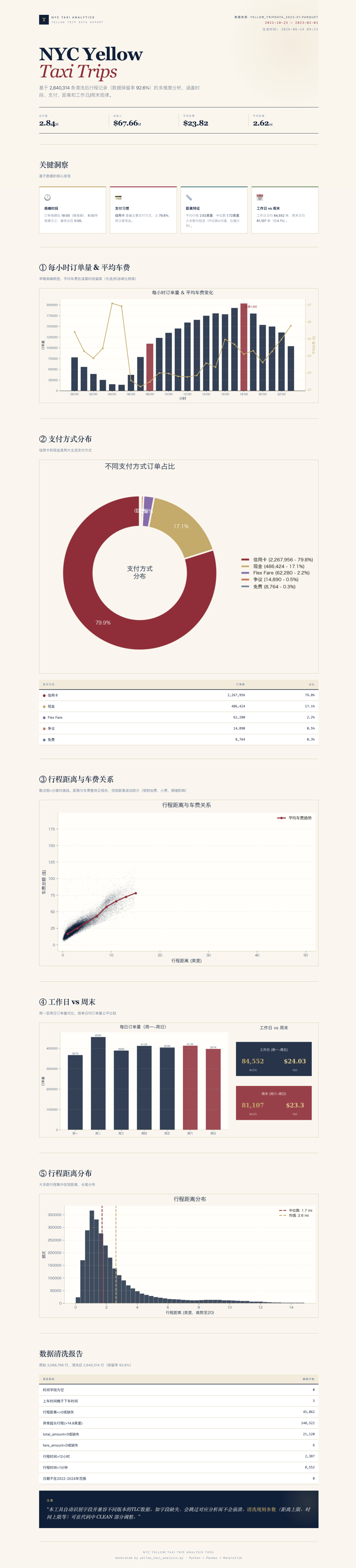
报告顶部给出总览指标,包括总行程量、总收入、平均车费和平均行程距离;下面则展开不同维度分析,覆盖每小时订单量和平均车费变化、不同支付方式订单占比、行程距离与车费关系、工作日和周末对比、行程距离分布,以及数据清洗记录。
其中,支付方式图表显示银行卡支付占比接近八成;工作日和周末对比里,报告也把订单量、平均车费等指标拆开呈现。更关键的是,报告底部保留了数据清洗说明,告诉用户哪些数据被剔除、哪些异常被处理。
当然,这类工具仍然需要人工调试。真实数据字段复杂时,字段名适配、图表样式、异常阈值都可能需要继续调整。但从这次结果看,Seed 2.1 Pro已经能把一个模糊需求推到可用边缘。
这正是专业版应该解决的一类问题。它们重要但零碎,常见但不值得大动干戈。
测试3:英伟达年报能不能让办公任务模式跑完流程
第三个任务,我们换到豆包桌面端办公任务模式,用2.1 Turbo处理一份NVIDIA 2025年Annual Report。
这次考察的是它能不能处理长PDF,包括提取财务数据、拆解业务板块、整理风险因素,并生成一份中文产业分析简报。我们还进一步要求它输出可视化结果,并放到本地桌面上。
Prompt如下:
Plain Text
你是一名科技产业分析师。请基于我上传的NVIDIA 2025 Annual Report,输出一份面向中文读者的产业分析简报。
要求如下:
1.用200字概括英伟达这一财年的核心变化;
2.提取收入、毛利率、净利润、研发投入等关键财务指标,并整理成表格;
3.分析Data Center、Gaming、Professional Visualization、Automotive等主要业务板块的变化;
4.找出报告中提到的3-5个核心增长驱动因素;
5.找出报告中提到的3-5个主要风险因素;
6.结合年报内容,分析AI基础设施需求对英伟达业务的影响;
7.输出一段“如果写成中文科技媒体稿件,可以怎么切入”的选题建议;
8.列出至少5个事实风险点,提醒哪些判断不能写过头;
9.最后用500字写一版中文摘要,要求表达自然,不要像财报翻译。
注意:
- 所有数字必须来自年报原文;
- 如果某个数据没有找到,请写“未在文档中找到”,不要编;
- 不要加入年报之外的信息;
- 不要把公司表述直接当成第三方结论。
包办公任务模式的价值,不只体现在对话框里回答得怎么样,也体现在它能否连接本地电脑、读取本地文件,再把分析结果转成一个可交付文件。
从过程看,办公任务模式会先理解需求,规划生成桌面端HTML或Markdown报告,再结合授权的本地路径执行保存。这类体验,已经接近AI替用户跑一段办公流程。
最终它输出了一份题为“NVIDIA 2025财年产业分析简报”的报告。

这个结果说明,2.1 Turbo在办公任务模式里,已经能完成比较完整的信息提取和结构化整理。
从专业版角度看,这个结果也提供了一个参照。免费用户能体验到2.1 Turbo办公任务模式,说明豆包想先让用户感知AI跑任务的价值。专业版真正要拉开的差距,应该体现在更强模型、更高额度、更复杂多轮任务、更稳定工具调用和跨文件处理能力上。
Seed 2.1为什么被推到台前?
这次火山引擎把Seed 2.1的重点放在Coding、Agent和VLM三个方向。巧的是,它们也更容易和生产力付费形成对应关系。
先说Coding。
过去很多人理解AI Coding,主要是让模型补一段代码、解释一个报错、写一个函数。到了专业版语境里,Coding能力的价值范围会明显变宽。
它可以帮开发者完成代码修改、自测和脚本生成,也可以帮非程序员把一个业务想法变成可运行的小工具。比如数据仪表盘、客户反馈表、项目管理看板、活动报名系统,都属于很多团队里“有价值,但未必值得排研发排期”的需求。
豆包专业版里的应用生成方向,和这一点是对应的。办公任务模式可以创建、修改、部署网站应用,支持开发带有后端数据库的在线应用系统,未来相关能力还会继续灰度和上线。
Agent能力对应的是另一类问题。
它考验模型能否理解目标、拆解任务、调用工具,在遇到异常时调整路径,并把任务持续推进到交付结果。
豆包办公任务模式的产品设计,正好把这种能力放进桌面环境里。它支持操作本地电脑和浏览器,在用户授权后,可以协助使用电脑里的应用、浏览器和文件,完成整理本地资料、归类文件、处理文档、填写表格、跨应用协作等操作。
过去聊天模型主要提供答案。办公任务模式想做的,是让AI进入电脑、文件、网页和办公软件之间的缝隙,接手那些原本需要用户不断切换窗口、复制粘贴、整理格式的工作。
VLM和复杂文档理解,则决定了专业任务的上限。
专业用户交给AI的任务,大概率不会只是一句话。它可能是一份PDF、一张表格、一组截图、一段视频、一个网页,也可能是几类材料混在一起。
Seed 2.1在多模态方向的提升,决定它能否处理这类复杂输入。再往下,Office应用、创意设计、可视化Skills、金融专业Skills等能力,都是把模型能力封装进更具体的流程。
从官方披露的评测看,Seed 2.1在Terminal Bench 2.1、SWE-Pro、SciCode、NL2Repo-Bench等Coding相关评测中进入第一梯队,Agent和多模态方向也在OSWorld、MobileWorld、MMMU-Pro等评测中位居前列。
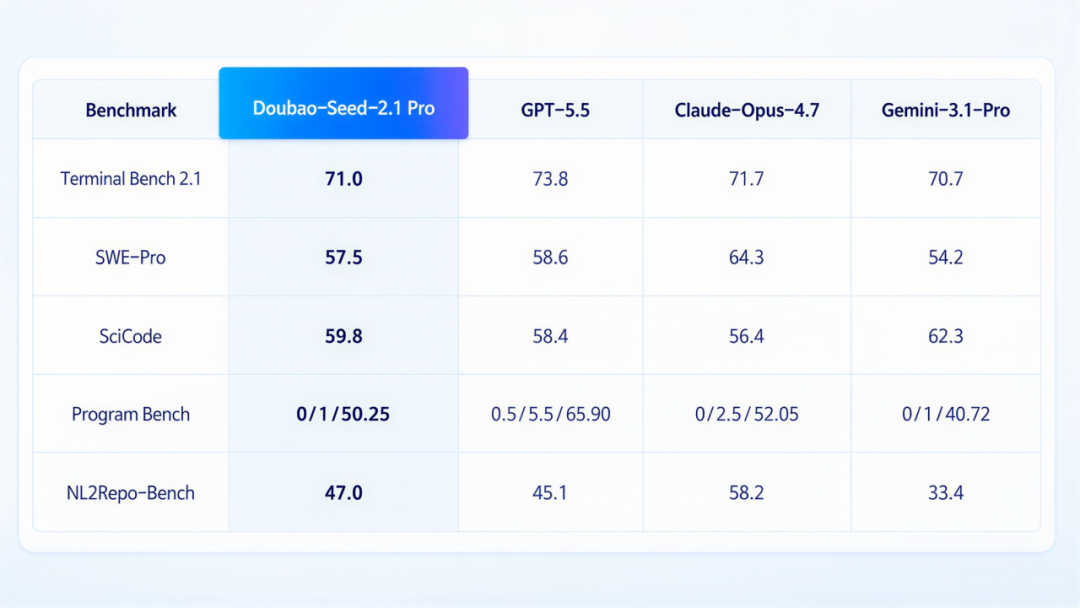
当然,榜单不能替用户做决定,但它至少说明,Seed 2.1这次提升的方向,和专业版要解决的问题是对得上的。
发布会里还有一个芯片设计RTL案例。Seed 2.1 Pro连续运行近18小时,经历多轮迭代,跑通仿真、测试、综合检查等完整流程,最后交付可用代码。
这个案例的重点,是它提供了一个参照,AI Coding的价值正在从写代码片段,走向跑完整工程链路。
对专业版来说,用户期待的也正是这种变化。
生产力质变点,最后要落到真实流程里
在昨天发布会之后,火山引擎总裁谭待在接受《划重点》等采访,谈到模型定价时说,看模型价格不能只看价格,要结合价值看。模型能做更多事情,创造的价值更大,单Token创造的价值也在上升,所以性价比是在提升。
这句话其实正好解释了豆包专业版的定价逻辑:用户真正购买的,不是Token本身,是Token背后能完成的任务。
谭待反复提到“生产力质变点”,这个概念背后其实有一套判断标准,要看模型有没有进入真实流程,能不能达到某个行业既有流程里的要求,最后能否通过数据和交付结果证明自己。
他举过Seedance 2.0的例子。
在Seedance 2.0之前,视频生成更像UGC玩具,周末调用更多;Seedance出来后,工作日负载和使用次数更高,说明它开始进入办公、生产、数据合成等场景。换言之,真正的变化,不只来自生成效果变好,也来自使用场景从休闲走向工作。
这套逻辑放到Seed 2.1身上也是一样的。简单Demo不算生产级。能跑进真实流程,能处理异常,能交付结果,才更接近生产力工具。
这也是为什么我们更关心刚才三组实测里的交付感。电商数据分析里,它要处理脏数据、算指标、给建议;出租车数据可视化里,它要写代码、做图表、生成HTML报告;英伟达年报分析里,它要读取长PDF、提取数字、生成本地可视化文件。
这些任务没有特别炫技,却更接近专业用户每天会遇到的问题。但AI产品收费能否成立,最后往往也会落在这些地方。
最后,回到我们最开始的那个问题——Seed 2.1值这个价吗?
现在更稳妥的答案是,它已经给出了一个值得继续观察的前提。
如果用户只是轻度聊天、偶尔写文案、问几个生活问题,免费版大概率已经够用。豆包官方也在强调,现有免费功能和额度可以满足大部分日常生活场景。
但对于高频处理文档、表格、代码、报告和可视化任务的人来说,专业版的价值开始变得具体。
因此,豆包专业版正式上线后,收费已经不是悬念。真正进入检验期的,是Seed 2.1和办公任务模式。
如果专业版只是更高额度、更少限制,它很容易被用户拿来和普通会员比较价格;如果专业版背后是2.1 Pro模型能力,加上办公任务模式、本地电脑连接、文件处理、Coding、Agent、Skills技能和多模态生成,它就有机会变成一套面向重度用户的AI生产力套餐。
虽然价格已经出来了,但答案还要看用户。因为用户愿意为AI付费,往往来自一个很朴素的理由——
它真的把一部分工作接了过去。